重启尘封十年的代码!回到未来的人人网,如何用新技术唤醒老数据?
作者|刘俊寰 来源|大数据文摘(ID:BigDataDigest)
在某个特定时间,我们都会想,如果能回到过去,当时不那么做,会不会是不一样的结局。
“将‘穿越时空’变为一道谜,变成故事里最浪漫的一件事”,这是最近大火的台剧《想见你》的预告海报中编剧之一林欣慧所写的话。在这个看似简单的穿越故事里,男女主人公分别穿越到未来和过去,试图改变命运,但是在时空交错之中能改变的有多少呢?

官方预告海报
处在2019年和2020年的交叉口,10年代的结束似乎正是缅怀过去的最好时机。如果有能力回到过去,你最想改变的是什么?
这是穿越到未来的人人网想知道的问题。
是的,你没有听错,就是中国最老牌的社交平台之一的人人网,在踏入Fintech、区块链、直播、二手车等领域的1400多个日日夜夜后,在2019年最后一天,人人网宣布重新回归社交,“人人”APP 1.1.0版也登陆各个应用市场,以“记录我的青春”为主题,正式开始公测。
00后们可能都没听过人人网,但对于文摘菌一样的80、90后们而言,这可是满满的青春回忆!人人网曾是中国规模最大的实名社交网络,在2005-2015近10年的时间里引领校园社交市场,在校园社交占据着绝对优势。2010年底,人人网的注册用户超过1.7亿,活跃用户超过1亿,到了2012年,人人网更是占据大学生市场75%的份额。截至2017年9月30日,人人网拥有2.54亿激活用户。
经历了后续的起起伏伏之后,2018年底,人人网被多牛传媒正式并购。据官方数据显示,至今为止,人人平台保存有超过70亿张用户上传的照片,百亿级的状态信息,而这些信息,不就是帮助我们回到过去的那盒伍佰老师的磁带吗(在剧中男女主角正是通过这首歌实现穿越的)?
十年前,“大数据”的概念还没有真正出现,而人人网上累积的数据事实上早已达到了大数据量级。在大数据和机器学习等新技术趋于成熟的今天,如何让这些PB级的数据重新焕发生机,就成了人人网研发团队首先要面对的问题。
同时,人人网还必须面对如今竞争激烈的社交软件市场。回想2019年初,扎堆出现了马桶MT、多闪、聊天宝等社交软件,其中聊天宝和多闪在上线当天还登上了App Store免费榜第一。
“内忧外患”之下,如何才能盘活人人网的生态?用今天的技术让曾经的数据焕发生机?
这就像是“复活”一个已经“死掉”的项目,多牛传媒COO鲁葳告诉大数据文摘,或许过程会很艰难,但未来回想起来应该还是挺有意思的。
重启尘封十年的代码,新老数据如何结合?
面对近十年累积下来的用户数据,多牛传媒研发中心副总经理曹兴宇坦言道,初次看到数据时感觉非常“头疼”。针对未来将如何利用老数据,他说道,新老数据不会完全结合,会进行相应更新。
但随着对数据的深入认识,研发人员才发现,数据本身尚未构成太大问题,数据的存储、在中间层和应用层的访问等,都远比预料的要轻松很多,真正让人感到头秃的是架构问题和代码问题。

人人网“退隐”的这十年是互联网行业飞速发展的十年,硬件、大数据计算、性能都有很大的提升。但是反观人人网,十年迭代,遗留的数据架构的可维护性等性能很差,鲁葳透露道,人人网的整体架构是叠床架屋一般一层层往上垒的。如果想在当年大数据架构的集成模式基础之上做出新东西,就不能一刀切,带着新旧两套轮前进,持续了很长时间。
同时,曹兴宇也举例回忆道,十年前Java因本身对内存优化没有做到极致等原因,对服务器的要求比较苛刻,大数据同理;不过当时人人网的工作思维十分现代,用人力解决了很多复杂的问题,不过也给他们带来了大量的后期工作。
如今,重新打开尘封已久的代码,除了感叹技术更迭之快,面对前人的努力,鲁葳也十分惊喜感动。
“可以说,人人在还没有微服务概念的时代做出了微服务架构能实现的能力,只是分布式架构中还存在单点耦合,逻辑复杂到一定程度后还是一团乱麻,虽然构想很聪明,做得也很辛苦。”
虽然受限于技术发展,但从遗留的代码中可以看出,人人一直在试图创新,比如当时的数据存储和计算就已经用到了Hadoop,不过现在来看还十分臃肿,整理工作仍不可少。
人人项目经理孟达介绍道,在图数据的处理上人人当时就已经做出了基于人际关系的检索和逻辑,而且,在人脸检测方向也已经有所进展,他们的思路是通过打标签等UGC方式来确定人物关系,这是十分超前的。
这些数据都还保留着,鲁葳说,需要进行更深一步的数据挖掘,如何利用机器学习让这些历史图片变得好玩起来,他们还在摸索。现在社交网站的人脸检测功能多用于照片裁切、主体识别等,他们希望能将其与时域和地域等要素结合,开发出更多的功能。
曹兴宇补充道,看到前人们的尝试,他们的压力很大,现在行业内的预测、推荐等功能都已经足够成熟,他们想把更多有意思的技术带到人人中去。
另一个让人头疼的是代码迭代问题。孟达说道,在这十年中,考虑到人人网的人员流动比较频繁,经常出现代码注释对不上的情况,还会遇到不同的代码语言,这需要配备专业人员去理解,难度很大。
在正式接手人人网数据后的这12个月内,除上述两大问题,人人网的项目组还需要开发业务、逻辑层面的功能,比如预测、人群画像等,以后还会做数据清洗,将旧数据对接到现在的大数据集群里,这也是项浩大的工程。
各种尝试唤回老用户,被遗忘权应该被尊重
虽然手握2.4亿老用户的数据,但是人人并没有将重心放在如何召回这些老用户上,让更多新人加入才是长期发展的方向,他们更希望将人人的生态盘活之后,让老用户自己活跃起来。
这便引发了另一个问题,互联网时代的用户大都是“金鱼记忆”,更别提十年前的账号密码了。正是考虑到这点,人人在如何找回密码上也下了不少功夫,除了利用UID检测和联系客服外,用户可以输入自己的信息,算法将匹配与该信息最接近的人,如果拿到账号后还不知道密码,可以利用人脸识别进行确认。

这种方法实践下来,鲁葳说,除了之前就被盗号的人,还没有人投诉过。而且,就算账号被别人拿走,一定也是与本人特别亲近的人,同时,在找回密码的时候需要提供身份信息,这也提供了另一层安全保障。
在利用人脸识别时,人人调用了第三方接口比对身份信息,引入了部分外部数据,也必定会引发用户对数据隐私的担忧。对此鲁葳介绍道,现在人人的很多数据处理都是交给机器来完成的。
此前Facebook因为开放平台受到了外界的广泛质疑,目前人人已经将开放平台的对外服务的接口全都停掉了,一些处理甚至超出了规定的数据隐私范围,而且在这方面技术和人工结合着在同步跟进。
鲁葳还说,被遗忘权是下一个需要解决的问题,对于百万分之几十打电话要求注销的用户,人人十分尊重他们的意愿,因此综合考虑后,上架的人人APP一个重要功能就是设置“新鲜事”仅半年可见。
也正是基于这方面的考虑,demo版的APP一开始也没有想往全社会推,但是被相关行业媒体注意到了,也就引起了大家的讨论。鲁葳笑着说。
通讯工具不等于社交网络,重返初心做好校园社交
在AI赋能全产业链的现在,不少社交平台也纷纷利用AI强化功能,就像1月初在广州举办的微信公开课,关于AI如何让搜一搜更智能的话题一度成为业界关注重点。
面对AI的技术趋势,鲁葳说,现在人人在机器判断违禁图方面已经申请了专利。这其中需要解决很多小问题,最初开源算法靠分辨肤色进行,到现在已经不灵了。现在人人在北京和深圳两个小组在内的十几位算法工程师在努力将风险识别从90%提高到99%,这是会长期做下去。
除此之外,对于人人网拥有的10亿级动态数据和几千万上亿级日志数据,内部的扫描程序也会一直进行更新提高效率。但遗憾的是,相关的NLP技术在多次与大学、研究所等专家交流之后得出的结论是,短期内无法实现工程化。
通讯工具不等于社交网络。面对竞争激烈的社交软件市场时,鲁葳这么说道,他说到前些年同样瞄准校园社交的几家竞品例如soul、即刻,其实都是存在差异的,而现在的校园生态相对来说还处于空白状态。
人人网选择现在回归,无疑将迎来巨大的挑战,但同时,这也是一次绝无仅有的机会。
调查显示,2018年中国移动社交用户规模为7.37亿,预计未来两年将稳步增长,2020年有望突破8亿人,在社交关系偏好方面,有57.6%的受访网民偏好纯熟人社交,而这正是人人的优势所在。
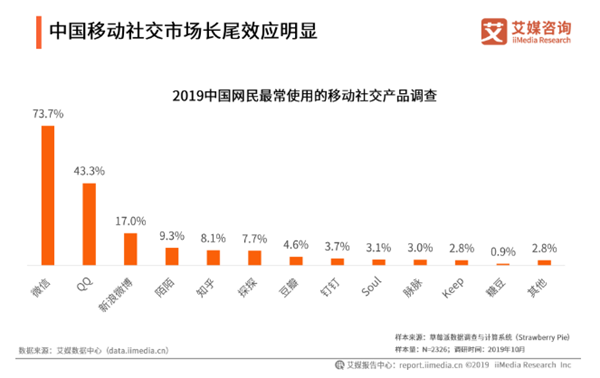
人人网告诉我们,他们想回到初心,重新瞄准校园社交,主要目标群体是离开家乡走向大学的、面临着社交关系重建的挑战的学生,帮助他们建立起相对自主的社交关系,这个断点是之前校内网关注到的,现在人人想继续做下去。
一个好的社交网络不是帮你交朋友,而是在社交软件中实现对现实社交关系的影射,如果用户在毕业后还觉得人人有用,在用户黏度上就无需太过操心。
如何做社交,鲁葳感慨道,10年前开拓的前人们没有想明白,大家就花了10年在这个行业里,相关的理论和总结都是一步步往前演进的。以至于到了现在,再来讨论做实名社交还是陌生人社交就比较外行了,这个分类方法就是有问题的。
10年前大家都还相信六度分割和邓巴常数,这么多年时间的实践证明邓巴常数是站不住脚的,而六度分割根本是个伪命题,现在每个人需要维护的线上社交肯定不止一个,使用的问题牵扯到需求强度、功能丰富度,以及能否包围用户需求等,两度分隔以上的人彼此都不会理睬了。
现在课程盒子等软件也都开发出了相关的校园社交功能,对此鲁葳表示,对于有创意的好的技术和功能,他们也会学习借鉴。
如今,人人网APP不断升级,更新更多新功能。面对武汉肺炎疫情的严峻形势,人人与中科闻歌进行合作,推出了“全国新型肺炎疫情数据”,助力疫情解决。其中,人人主要利用自身平台优势,进行数据的处理工作,做好相关疫情的关注和分享。
“与所有平台所有人一样,我们都希望这次的疫情能赶紧过去。“人人网告诉我们。

鼎盛时期的人人网团队有四五千人,光技术团队就有不少于三百人。而现在负责人人APP的技术团队只有大概50人,要重启这样一个曾经的社交巨兽,不是一件容易的事情。
对于未来的发展,鲁葳告诉大数据文摘,目前还有很多细节问题需要不断深入研究,也会跟同行学习,就现在人人了解和掌握的程度来说还远远不够。以后肯定是一个漫长的学习过程,最重要的是从用户身上学习。
编者按:文章转载自微信公众号:大数据文摘(ID:BigDataDigest),作者:文摘菌
品牌、内容合作请点这里:寻求合作 ››


前瞻经济学人
专注于中国各行业市场分析、未来发展趋势等。扫一扫立即关注。
前瞻产业研究院
中国产业咨询领导者,专业提供产业规划、产业申报、产业升级转型、产业园区规划、可行性报告等领域解决方案,扫一扫关注。相关阅读RELEVANT



























