“反英伟达联盟”背后,是AI的第三场战争

(图片来源:摄图网)
作者|启新 来源|锦缎(ID:jinduan006)
人类社会正在悄然从互联网时代切换到算力网时代。
鲜有人感知到的是,时代转折序曲中,遇到的第一批实体障碍,除了GPU、HBM,还有交换机——此前市场鲜有关注的交换机,正在扼住AI算力的咽喉。
全面出击的英伟达VS蓄势反击的联盟,是GPU、HBM之后AI的第三场战争:一场科技史上围绕交换机的精彩对决即将上演。
01
思科后遗症
如果用人体结构来类比AI算力,可以做如下理解:AI芯片(由GPU+HBM+CoWoS组成)是心脏,CUDA等加速软件是大脑,光模块是关节,线缆光纤是血管,以交换机为代表的网络设备是咽喉。不同的设备合集,最终呈现的是整个服务器集群。
其中AI芯片、CUDA、光模块、线缆,都已经被翻来覆去的讨论过无数回,成为阳谋。但令人诧异的是,为什么交换机作为核心的组网设备之一,却一直备受冷落,只能充当AI暗器。
根据定义,交换机(Switch),工作于OSI网络模型中的数据链路层,智能地决定将数据帧从哪个端口转发出去,从而实现网络中的数据交换和流量管理。因此,交换机的核心作用是提高网络的性能和效率,并支持网络的扩展和管理。通俗理解,交换机就是“网络效应”的硬件载体。
而且从市场规模来看,交换机也相当之重要。根据IDC《2023年网络市场跟踪报告》的最新数据,2023年全球网络设备市场规模为714亿美元,其中交换机超过400亿美元,是仅次于AI芯片、服务器的核心算力组件,规模甚至要远大于近期被火热讨论的光模块和高速存储HBM。
黄教主其实在公开场合也表达过交换机的核心地位。老黄曾透露,在AI整个集群投资中,InfiniBand网络(以下均简称IB)约占总成本的20%。这里简单科普一下,IB网络是英伟达在子公司Mellanox的帮助下,自己搭建的用在服务器之间的算力通信网络,其中所使用的核心交换机为自产的IB交换机。
既然从技术角度来看如此重要、从市场规模看也不小,怎么交换机就始终不被大家重视呢?
笔者认为,最主要的原因在于交换机被成见式的认为是网络架构中配角的存在,毕竟HBM、CoWoS这些新名词一听就是十倍空间起跳的宏大故事。而一提交换机,大家条件反射式的想到:这不就是2000年互联网泡沫时的思科的产品么,还能炒吗?
20多年前思科作为全球网络设备的绝对龙头,与现如今的英伟达享受的是一样的地位。在2000年,思科的网络交换机市场份额超过6成,路由器份额超过8成,可以说没有思科的网络设备,就不会有后来的互联网蓬勃发展,当年思科被誉为互联网卖铲人。
后来的故事大家想必每个人都知道了,随着互联网泡沫的破灭,思科的股价遭受了重创,从高点下跌了超过70%。公司后来用了20年,才勉强填平当年估值带来的狂热泡沫。科技行业天然“喜新厌旧”,交换机这个老面孔自然被绕着走,何况当年被深套的恐惧还深深刻在每个投资人的反射弧里。
但成见已经是过去式,当下时点,势必要重新审视对交换机、尤其是AI交换机的理解了。原因无他,各方面的信号已经非常明显,随便举出两例:
全球龙头企业,已经开始在新型交换机和网络架构上正面激烈交锋。除了上面提到的英伟达,其实超以太网联盟的动作也非常之大,后文会具体分析。
美股投资人也开始追捧交换机标的。在最新的AI交换机中,龙头毫无疑问是英伟达的子公司Mellanox,但是由于不单独上市和披露财务数据,看不到太多细节;第三方AI交换机的龙头不是前文提到的思科而是后期之秀Arista,其股价在2023年上半年第一轮AI浪潮中之中没有跑赢纳斯达克,但是自2023年底开始加速上涨,这显示美国投资人正在重新审视它的重要性。
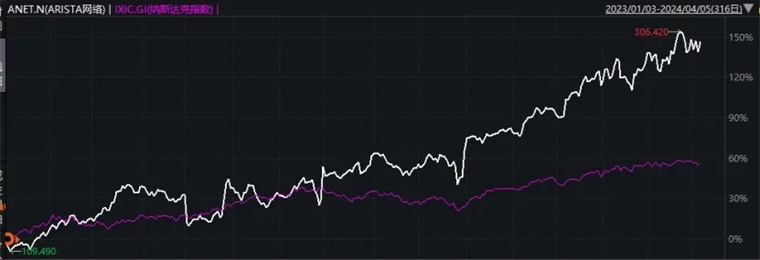
图:高速交换机龙头Arista股价开始加速上涨
02
第三堵墙
今天再度重新认识交换机必要性,就缘自交换产品的本身发生了重大变化,而且交换机在网络中的重要性也在明显提升,甚至已经成为AI基础设施中的三堵高墙之一。
1、AI催生算力网革命
似乎网络架构已经停滞很久了。如果深究网络架构的变迁史,不难发现OSI网络模型上一次大的变革,还要追溯到十多年前云计算爆发时期的“网随云动”。在停滞十多年后,我们观察到,AI将催生互联网络设备的最新革命,将促使网络架构从互联网时代切换到算力网时代。
算力网该如何理解?首先说以前互联网中网络设备的核心任务,是完成即时通信,所以交换机本质上是一个通信设备;而现在AI算力中心中网络设备的构建逻辑,在于集中力量办大事,即集合越来越强大的算力,交换机不再仅仅是通信设备,而变成了算力设备本身。
想必有很多人在这儿会持反对态度。不用着急,请继续看后面的解释。
众所周知,这一轮AI能够成功是大力出奇迹的工程学突破,背后的指导法则是“scaling law”,scaling law描述的模型性能与模型规模之间的幂律关系,这一法则表明,当模型的规模(例如参数数量、数据集大小和计算资源)增加时,模型的性能将得到提高。
换句话说,为了得到AI大模型智能的涌现,scaling law告诉你要不停的堆算力和数据。这也是为什么,在2024年3月初,黄仁勋斯坦福大学演讲时提到,在未来的10年里,英伟达会把深度学习的计算能力再提高100万倍。这并不是泡沫时期的大放卫星,而是AI智能涌现的必要条件。
算力要实现如此恐怖的提升幅度来满足scaling law,从硬件的角度来分析,路上有三堵墙:
1)算力墙:核心围绕GPU,也是大家在AI算力硬件中关注度最高的产品。破除算力墙最关键的技术手段是制程和芯片架构的升级。但制程带来的单芯片算力提升面对着黑洞般的AI需求,已显得苍白无力。毕竟现在的苹果最新的3nm的A17芯片,升级的效果已经微乎其微。实际上,英伟达的GPU,采用的只是4nm制程,甚至下一代产品B100,也不会升级到3nm。每一代际算力倍增可能已经是单芯片算力提升的极限了。
2)存储墙:核心围绕HBM。单芯片算力跟不上,可以靠HBM来大大缓解,在《AI国力战争:GPU是明线,HBM是暗线》一文中有详细讨论,可以移步于此。HBM反倒成为一个飞速进步的环节,海力士和美光最近股价飙升便是市场开始认知到这一方向的重要性。
3)通信墙:算力和HBM结合在一起解决单卡的问题,但单卡再强也远远跟不上下游的算力需求。进一步的解决方法是堆料,抛开复杂的技术名词,其实原理就是简单粗暴的大力出奇迹,把尽量多的优质的算力卡连起来组成算力集群,这与猎鹰火箭装27台发动机本质上是一个道理,其中的关键技术就在于数据中心的组网技术,因此,交换机的地位今时不同往日。
从最新的英伟达GB200计算集群网络架构中,我们能够非常清晰的看到多处堆料组网的技术:1)GPU卡与GPU卡之间,基于NVLink协议的卡间互联,这部分配套的switch芯片,由于被英伟达垄断,没有太多产业链探讨的意义,因此不再展开。2)再往上一层,就是IB交换机,它连接起多个GPU卡群,构成一个完整的机柜Rack。3)多个机柜再通过交换机互联,形成强力的AI算力中心。后面两个环节,都离不开AI交换机的支持。
这种架构就能非常清晰的看到,为了突破通信墙打造强大的算力基座,交换机不仅仅是充当算力网络中的通信设备,而自身也变成算力设备的本身。正是这一产业链环节定义的变化,给了整个交换机产业链拔估值的基础。
在这一轮算力网革命中,交换机正式与GPU、HBM、先进封装、光模块一道,站到了产业链的C位。

图:GB200计算集群网络架构,来源:英伟达官网,中金公司
2、初听不识曲中意,再听已是曲中人
其实,产业链的这一变化不是2024年英伟达通过GB200才向全世界摊牌的,最早的信号发端于5年前。
2019年,英伟达豪掷69亿美元,击败英特尔和微软收购了彼时绝大部分都还比较陌生的Mellanox。笔者当年也是不理解一个芯片厂玩什么交换机,只是觉得这对于财大气粗的英伟达来说,算一个不大不小的收购,自然也是没有仔细分析产业链上的协同效应。
但随着AI算力爆发,Mellanox的重要性飙升,成为英伟达IB交换机、Spectrum-X以太网交换的御用供应商,占据了AI网络设备中的最高份额。毫不夸张的说,现在Arista市值接近1000亿美元,Mellanox可以轻松给到3000亿美元,较当年看似极其溢价的69亿美元升值43倍,远超这5年英伟达的市值上涨幅度。
老黄当时就对这笔收购非常得意,曾说这是两家全球领先高性能计算公司的结合,早在5年前就已经把Mellanox放在与英伟达同等重要的位置上,回头来看不得不感叹老黄的眼光确实毒辣。
Mellanox,凭什么能跟英伟达平起平坐?Mellanox提供的主要产品是数据中心内的通信互联解决方案,而其中最为核心的又是基于IB协议开发的一些列网络设备产品,这儿有必要展开说一下IB协议。
1999年,北美计算机巨头们牵头组织IB联盟,目的是为了取代PCIe总线协议,成为智能设备之间互联的新的协议标准,IB内嵌了RDMA(Remote Direct Memory Access)功能,能将服务器间内存、GPU内存直连;比如在AI的GPU集群中,RDMA技术能加速卡之间的交互,大大节省时延。
但IB后来声音日渐变小,而智能设备之间的互联,仍然是由性价比更高的PCIe协议牢牢占据了核心位置。这是由于IB协议需要专门的网卡和交换机来支持,导致了居高不下的硬件成本,因此在跟以太网的方案中竞争中败下阵来。头等舱是好,但没有几个人坐得起。
后来连IB首发者英特尔都选择了退出,最终只有Mellanox苦苦的在这条“错误”的路线上坚持。Mellanox公司成立后不久,便加入了IB联盟并推出相关产品,到2015年,Mellanox在全球IB市场上的占有率达到80%,虽然领先但在这一小众市场不被人注意。2019年被英伟达收入囊中,而这之后,IB基本从一个公开协议变成了英伟达的私有协议,更不为人关注了。
直到2023年这个算力为王的时代,IB协议才一飞冲天被广为人知。AI大模型的横空出世,算力的缺口一下子被放大到无限大,而作为并行计算中关键加速器的IB协议,成了最优解决方案,这一协议的硬件载体,正是IB交换机。
在英伟达及旗下Mellanox的强势带领下,市场纷纷上调高速交换机的出货量,IDC预计2023-2024年,市场高速交换机增速分别为54%和60%,2024年甚至还呈现加速的迹象。由于Mellanox是英伟达的子公司没法直接投资,美股投资人转而追捧最纯正的交换机标的Arsita,毕竟它虽然不如Mellanox优秀,但也是各大云厂商高速交换机的最大供应商。

以点带面,通过高速交换机这个纽带,我们不难发现,信息革命已经从互联网进入到算力网的时代。如果在今年,你还只在聊互联网,显然已经被时代甩下了车;同样,如果聊算力还只在聊GPU,显然三大重点你只抓住了一个。
03
“失意者联盟”
1、英伟达+mellanox在干什么:意欲吃干抹净
从交换机的产品谱系图,我们更能读懂英伟达的布局。这张图其实信息含量极大,建议反复观看。
首先说,英伟达的野心很大,它从来都不是只想做一个卖卡的芯片公司,而是想做AI时代的算力方案解决商。或者说英伟达商业模式的变化:从来不只是想卖铲子,是卖给你整个矿山,别再用“卖铲人”来形容英伟达了。
英伟达2021-2025年的产品路线图,昭昭然的将这个野心公示全球。其中标粗的是其核心的GPU产品,从A100迭代到H100,然后再到今年的B100,再到2025年的X100,路线非常清晰,也是AI产业链关注的焦点。
但经常被忽略的是图表的下半部分,英伟达同时标注出了配套的交换机型号变化,分为两个IB和以太网两个系列方向:
选用英伟达IB协议的,配套的是由Mellanox提供的Quantum系列交换机,将依次对应从400G升级到今年的800G,再到明年的1.6T。值得一提的是,在这个过程中,光模块也需要对应从800G升级到1.6T然后到3.2T,Mellanox也可以部分提供。
现在很多客户由于只能采购英伟达的GPU,已经非常被动了,因此很多企业并不情愿采购IB方案,仍坚持以太网方案。对于这种客户,英伟达也可配套提供Spectrum-X系列的以太网交换机,同样也是将依次对应从400G升级到今年的800G,再到明年的1.6T,只不过互联效率要弱于IB方案;这几款交换机也是由Mellanox来提供。
选用英伟达IB协议的,配套的是由Mellanox提供的Quantum系列交换机,将依次对应从400G升级到今年的800G,再到明年的1.6T。值得一提的是,在这个过程中,光模块也需要对应从800G升级到1.6T然后到3.2T,Mellanox也可以部分提供。
现在很多客户由于只能采购英伟达的GPU,已经非常被动了,因此很多企业并不情愿采购IB方案,仍坚持以太网方案。对于这种客户,英伟达也可配套提供Spectrum-X系列的以太网交换机,同样也是将依次对应从400G升级到今年的800G,再到明年的1.6T,只不过互联效率要弱于IB方案;这几款交换机也是由Mellanox来提供。
所以,在老黄的构想里,如果一个超算中心是专门为AI建的,那就用最快的IB交换机方案;对于存量的以太网算力中心,如果客户扭扭捏捏,英伟达也能匹配提供以太网方案,就用Spectrum-X交换机。简单来说,就是面向现在和未来的生意英伟达给你包圆了。
从图中也能看到,英伟达不仅仅只是想同时卖芯片和交换机,它的野心远超于此。
如果客户同时选购了英伟达的芯片、交换机,就离采购英伟达AI算力集群方案不远了(图表的上半部分)。在整体方案中,英伟达给下游客户推自有GPU+自有网络设备+自有CUDA搭建的整个AI算力集群。这就是AI工厂的模式,价值量将是只卖GPU卡的数倍以上。
更为重要的是,如果整个图实现,这一轮的AI大潮将被英伟达实现新版的软硬件解构,软件企业如云厂商负责疯狂氪金和试错商业模式,硬件企业英伟达负责建AI全算力和旱涝保收。
有必要提的一句题外话是,这张图也能看出英伟达并不准备染指HBM和先进制程,台积电和海力士目前来看还是非常安全的。

图:英伟达产品路线图
2、英伟达恐惧症:反击者联盟
别看各大厂的老板,求着老黄买卡是对英伟达态度非常好;但实际上,对英伟达恐惧在硅谷正与日俱增,大佬们都在牌桌底下热议如何摆脱。面对英伟达如此凌厉的明牌攻势,此前一盘散沙的非英伟达阵营也展示出了空前的团结。
GPU芯片和CUDA网络,似乎壁垒过高,尽管比如谷歌已经死磕TPU多年,但收效甚微,更多人是选择了躺平接受了英伟达在GPU上垄断的现实,所以英伟达的GPU才能毛利率高达90%以上,堪称有史以来最暴力的硬件。
而交换协议和交换机,由于技术壁垒相对低,且处于产业变革的早期,成为众人攻破英伟达堡垒最优的一致选择。
至此,交换机这一长久以来不被重视的网络设备,一下子跃升为AI算力基础中的暗战高地。为了追赶英伟达IB方案,2023年7月,“超以太网联盟”(Ultra Ethernet Consortium)正式成立,这一联盟迅速成为各个大厂的救命稻草。英特尔、微软、Meta、博通、AMD、思科、Arista、Eviden、HP等陆续加入。
超以太联盟成立后,便马上推出了RoCEv2(RDMA over Converged Ethernet)方案,在软件层吸收了前文提到的关键技术RDMA,剑指的方向非常明确,那就是力争对标IB性能。
以太网的后发优势目前看有两个:
根据产业链调研,英伟达的IB方案比以太网方案贵20-30%。以太网方案可以通过主打性价比来扳回一局。
人多势众。传统的数据中心,基本都是以太网协议,对于升级到超以太,兼容性要好得多,毕竟协议就是硬件对话的语言,用的人多自然就成了主流。
在超以太联盟中的GPU全球老二AMD,把这两点说得更加清晰:以太网将成为AMD构建算力集群的基础协议,因为以太网拥有更好的性能、更强大的大规模集群能力,以及最为核心的开放性,希望与头部交换机厂商一起,降低组网成本,打造更具性价比的网络。
也正是基于这两点原因,不少人对于超以太网联盟还是很有信心的。到底是以太网胜出,还是IB一统天下,最终答案只能留给时间来验证。但不管怎么样,英伟达与超以太联盟的这轮对垒应该是非常精彩的,必将成为科技史上日后被人反复提及的经典桥段。
但笔者倾向于认为超以太网的胜算还是被高估了。因为Scaling Law的指导之下,AI算力网络比拼是速度不是价格,人多如果不是最优方案,那可能也只是乌合之众。这就像自行车肯定是更经济的出行方式、骑的人也多,但是没有人会用它来上高速,留给以太网联盟的时间其实不多。

图:超以太网联盟
3、国产还落后以太网联盟半个身位
本来行文至此就可以收笔了,但估计还有不少人关注国产算力网络中交换机的进展,在此再赘述一二。
在互联网时代的算力基础设施投资中,得益于运营商的超前投资,我国的基础网络速度、渗透率在全球都处于领先地位,这也在后面直接催生了中国的移动互联网繁荣,中国的互联网公司,也因此具备全球竞争力。
不少人认为,我们在AI时代,也可以依葫芦画瓢,上演后来者居上的戏码。
但不得不直面的遗憾现实是,而在算力网络时代,我们的算力基础设施处于全面落后状态。我们不仅仅在GPU、HBM、先进封装方面有不少课要补,代表着算力集群能力的交换机我们也并没有什么优势可言。一方面我们并没有IB交换机,只能做以太网交换机,而且以太网交换机的代际更迭上也落后于海外1代,也就是落后超以太网联盟半个身位。
好在和其他网络设备一样,中国在交换机上其实一直具备很强的竞争力,这还要得益于华为20多年前的努力,以及孵化了后来的新华三。时至今日,国内的AI算力网络中的交换机仍然沿袭了骨干网和数据中心网络中的格局,新华三和华为依旧是主要的玩家。
种一棵树最好的时间是十年前,其次是现在。虽然在AI交换机上我们落后了不少,但依靠历史积累和集体的力量,如果从现在开始追赶,这一场对弈,我们未必不能上桌。
编者按:本文转载自微信公众号:锦缎(ID:jinduan006),作者:启新
品牌、内容合作请点这里:寻求合作 ››


前瞻经济学人
专注于中国各行业市场分析、未来发展趋势等。扫一扫立即关注。
前瞻产业研究院
中国产业咨询领导者,专业提供产业规划、产业申报、产业升级转型、产业园区规划、可行性报告等领域解决方案,扫一扫关注。相关阅读RELEVANT



























